Trio Retina¶
Turn any perception model's output into one standard, queryable world-state — symbolic events, with a latent-vector channel built in. The model-agnostic state layer for world models.
Retina turns raw signals — video, RTSP, files — into a queryable world-state: readable events (zone.enter, dwell, line.cross) plus a standardized latent vec channel on the same records, on one small model-agnostic standard. The latent channel is a real, serializable interface (attach your own embedding — see examples/latent_vec.py), and the automatic producers now ship: DinoV2Embedder fills per-object entity.vec and VJepa2Embedder fills the scene latent ws.scene. Bring any model (YOLO, V-JEPA, DINO, a VLM, or none); Retina assembles its output into state a dynamics model, rule engine, or LLM can consume.
Think OpenTelemetry for perception — it doesn't build the sensors, it normalizes any of them into one state. It isn't out to win a vertical — driving, games, and robotics each already have their own stack — it's the neutral state standard those structured, multi-sensor world models share. A world model leverages it four ways: one contract for many sensors, encoder ⟂ dynamics (swap either side without retraining the other), a state you can read/log/verify (observability even when the dynamics is a black box), and cheap encode-to-state at the edge. → see DESIGN.md.
Install¶
pip install trio-retina # core: numpy only
pip install 'trio-retina[yolo]' # + Ultralytics YOLO adapter
pip install 'trio-retina[video]' # + OpenCV frame source (files / RTSP / webcam)
pip install 'trio-retina[all]' # everything
Quickstart¶
Runs on a bare pip install trio-retina (numpy only) — no model, no GPU, no video file. A stand-in detector walks one "person" across a dock zone; Retina emits the real retina.event stream:
import numpy as np
from retina import CountRule, IoUTracker, Retina, Zone, ZoneRule
from retina.detect import Detection
class ScriptedDetector:
"""A stand-in model: one 'person' walking across a dock zone."""
def __init__(self):
self._xs = list(range(0, 102, 6))
def __call__(self, frame):
x = self._xs.pop(0) if self._xs else 100
return [Detection(label="person", bbox=(x - 10, 40, x + 10, 60), confidence=0.9)]
dock = Zone("dock", [(40, 0), (60, 0), (60, 100), (40, 100)])
cam = Retina(
source_id="cam_01",
detector=ScriptedDetector(),
tracker=IoUTracker(min_hits=2),
rules=[
ZoneRule(dock, classes={"person"}, dwell_s=2.0),
CountRule(1, classes={"person"}),
],
)
frames = [(np.zeros((100, 100, 3), dtype=np.uint8), float(i)) for i in range(18)]
for event in cam.run(frames):
print(event.to_json())
# {"type":"count.threshold","t":1.0,"src":"cam_01","n":1,"frame":1,...}
# {"type":"zone.enter","t":7.0,"src":"cam_01","id":1,"label":"person",...}
# {"type":"zone.dwell","t":7.0,...,"zone":"dock","dur":2.0,...}
# {"type":"zone.exit","t":7.0,...,"zone":"dock","dur":3.0,...}
With a real model + video¶
pip install 'trio-retina[yolo]' (add [video] for the frame source), then point it at your clip:
from retina import Retina, Zone, ZoneRule, YoloDetector
from retina.sources import video_frames
dock = Zone("dock", [(0.3, 0.2), (0.7, 0.2), (0.7, 0.9), (0.3, 0.9)], normalized=True)
cam = Retina(
source_id="cam_01",
detector=YoloDetector("yolo11n.pt", classes={"person"}),
rules=[ZoneRule(dock, classes={"person"}, dwell_s=30)],
)
for event in cam.run(video_frames("your.mp4")):
print(event.to_json())
Run it in your browser — no install¶
| notebook | what it shows |
|---|---|
| quickstart | detector → zone / line / count / dwell events + validate() |
| camera → webhook | a restricted-zone alert pushed to your endpoint |
| from Supervision | pipe your existing sv.Detections straight in |
More no-model examples ship with the source (not the wheel) — git clone the repo and run python examples/quickstart.py. See also rtsp_to_webhook.py, from_supervision.py, and latent_vec.py.
🌍 The world-model stack¶
Retina is the encoder (s = Enc(x)) of a world model. The whole front-to-back
seam is demonstrable end to end — on a synthetic scene, as a small, honest proof of
concept (examples/world_model/):
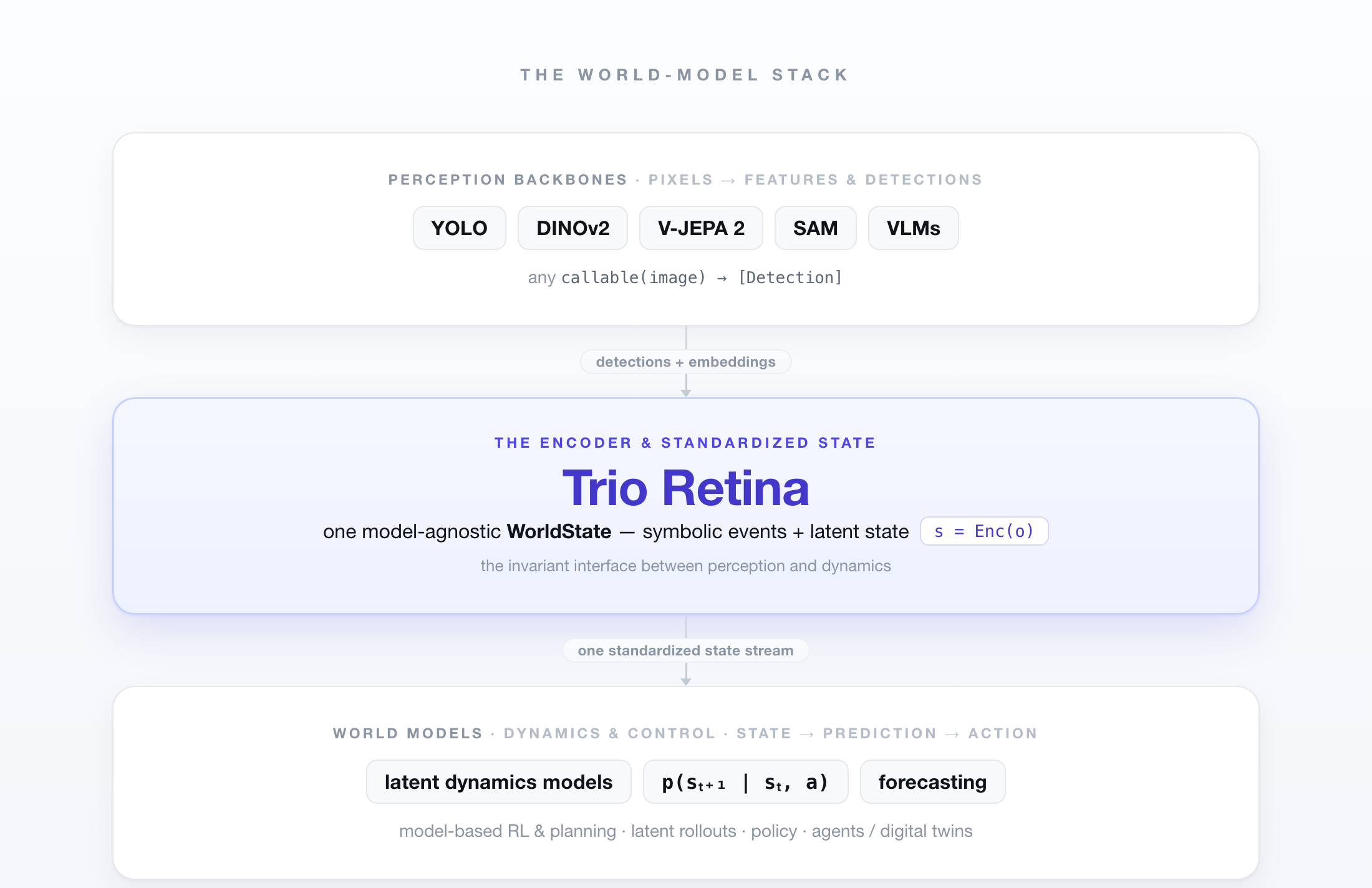
Any perception model on top, any dynamics model underneath, meeting on one standard WorldState — Retina is the constant in the middle.
1 · Swap the encoder, the state is constant. The same pipeline run three ways —
symbolic only, + DinoV2Embedder (per-object entity.vec), + VJepa2Embedder
(scene-level ws.scene) — yields the identical WorldState schema; only which model
filled the latent changes.
2 · A dynamics model imagines the future off that state. A small transformer
trained offline on recorded WorldState sequences predicts where each entity is headed.
The honest ablation — does Retina's appearance latent actually help? — on held-out
data with real DINOv2 vecs (mean 7-step position error, px, lower is better):
| dynamics input | 7-step error |
|---|---|
| constant-velocity baseline | 7.68 px |
| learned, pos-only | 1.45 px |
| learned, pos + appearance latent | 1.33 px |
The latent channel measurably improves prediction — +83% over constant-velocity,
+8% over pos-only, widening with the horizon. Full grid in
BENCHMARK.md.
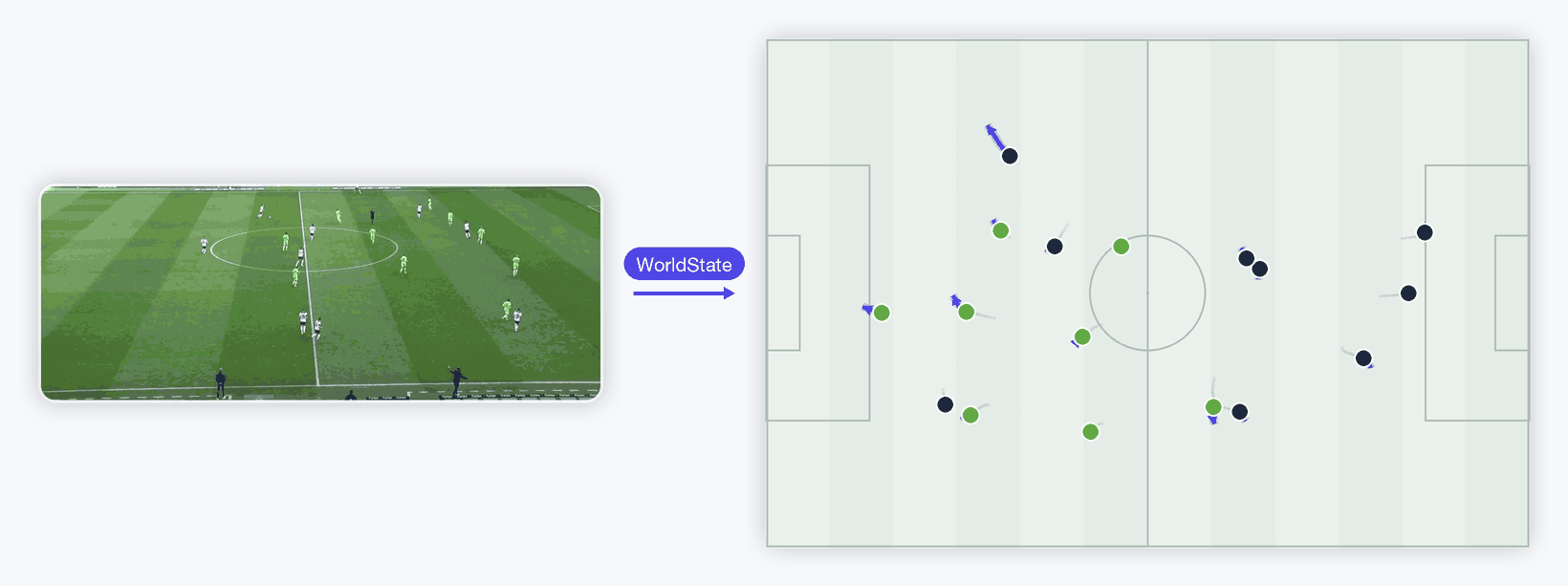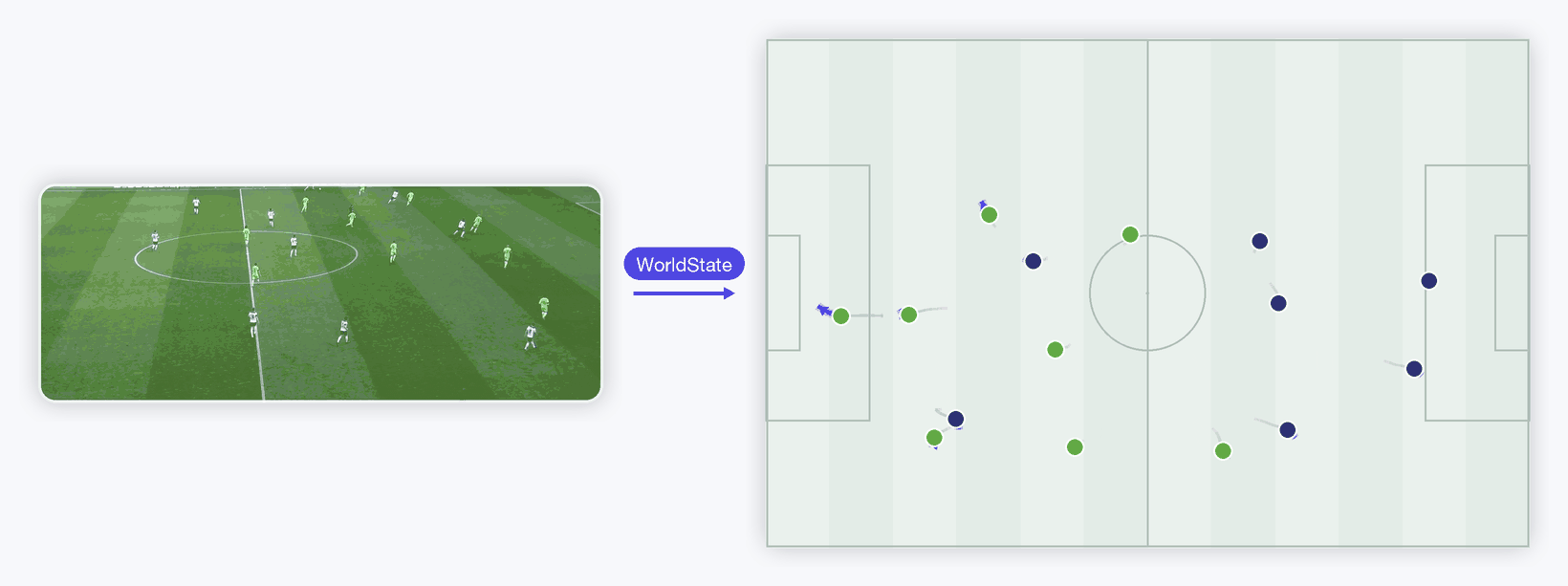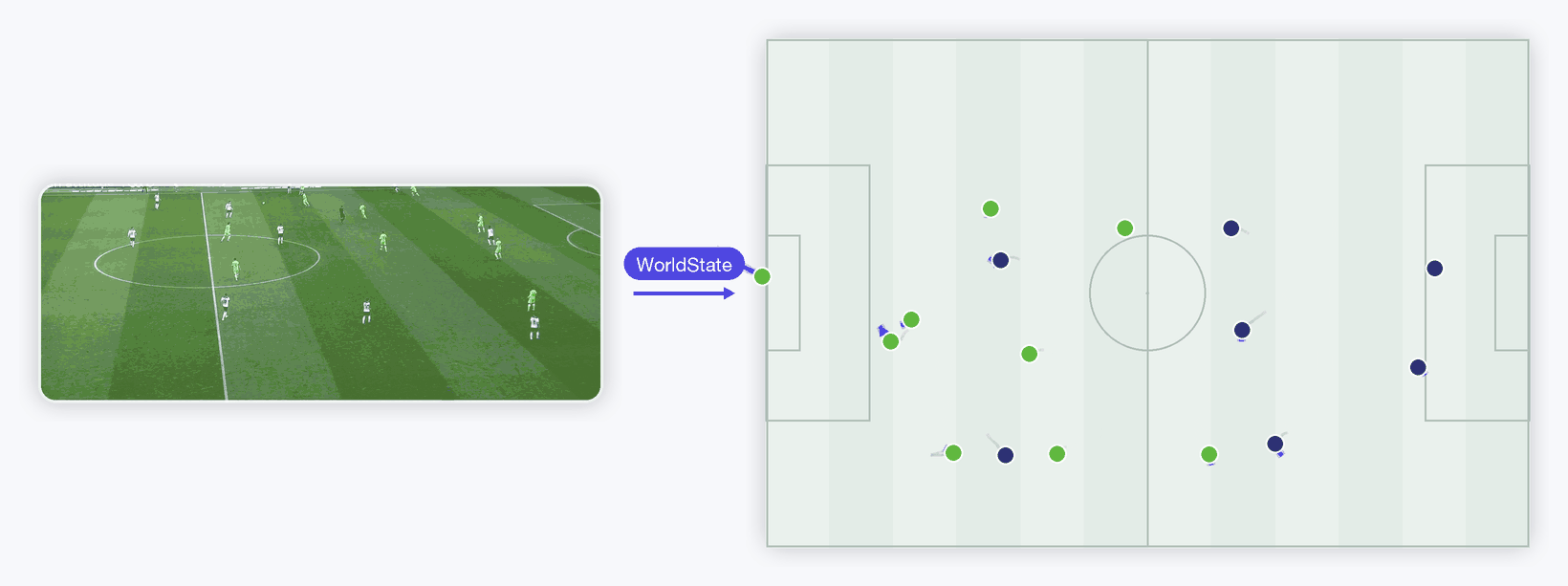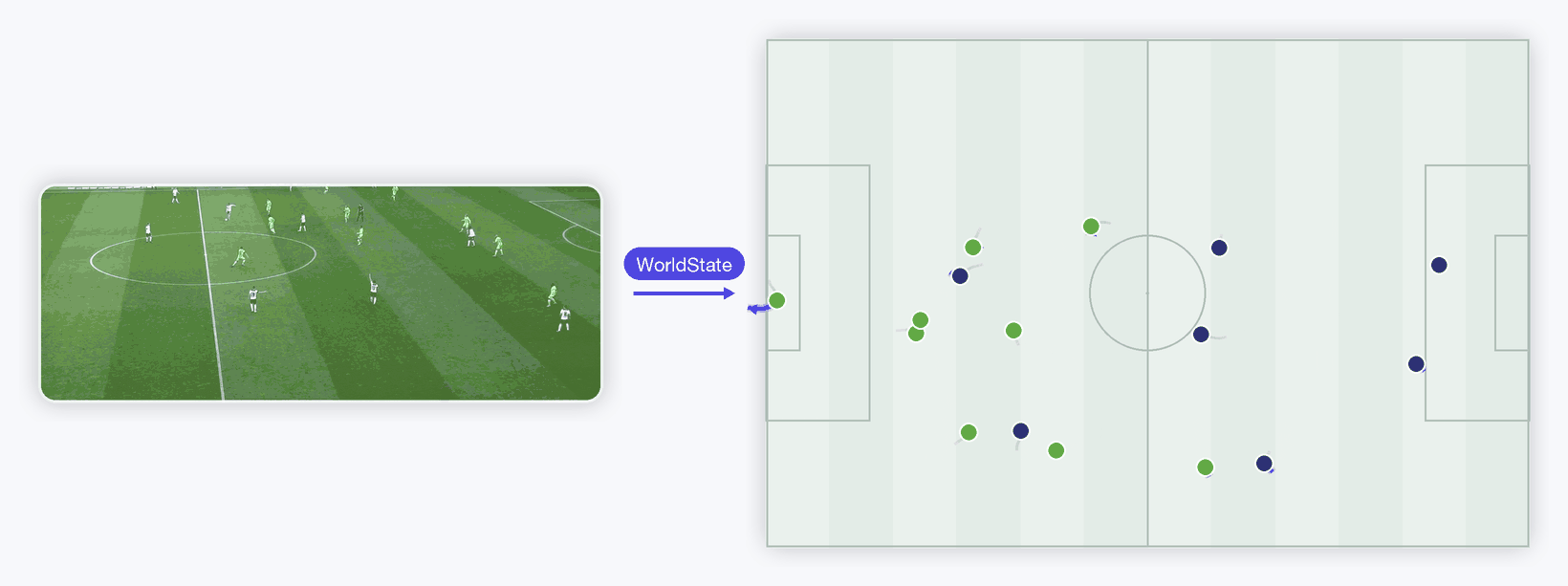
Raw video → one standardized Retina WorldState → predicted player runs. Left is a real broadcast clip (Roboflow's MIT-licensed sports sample, originally DFL Bundesliga); it runs through a real YOLO detector + tracker and a frozen DINOv2-small appearance encoder, out as one model-agnostic WorldState, rendered right as a top-down tactical radar. The dynamics transformer draws each player's predicted next run ahead in indigo (gray = past). Teams are coloured by clustering the DINOv2 appearance vectors into two groups — the latent knows who's who. Honest by design — player motion is stochastic, so at this short horizon the learned model roughly ties a constant-velocity baseline on held-out error; the appearance latent's measurable win lives in the cleaner synthetic ablation above. Real pipeline end to end.
3 · Front + back compose through one standard — any encoder in front, any dynamics
behind, meeting on one serializable state. See
end_to_end.py.
Where to go next¶
- Concepts — the mental model in one read:
Frame→Detection→Track→Event, the dual symbolic + latent state, and where Retina sits in the stack. - Cookbook — runnable task recipes (zone intrusion → webhook, counting / line-crossing, Supervision interop, latent
vec, validation, the CLI). - CLI —
retina demo/run/validate/bench. - Extend — add your own detector / tracker / rule / sink behind the tiny
Protocols. - FAQ — which extra to install, "no events?", RTSP reconnect, CPU vs GPU, where examples live.
- Event spec — the tiny, JWT-style
retina.eventinterchange format. - Design notes — why Retina is the encoder of a world model, and what it deliberately does not do.
- API reference — the public Python API, generated from docstrings.
No footage to test the video path? retina.sample_video() returns a tiny generated clip; retina.sample_events() returns a bundled retina.event sample for validate and the CLI — both work offline.
For the full landing page (demos, supported models, comparisons, roadmap), see the README on GitHub.