Concepts¶
The whole mental model in one read. Retina turns a stream of images into a standardized state + event stream — not boxes drawn on a screen. Everything below is one small, serializable, model-agnostic contract.
The data, bottom to top¶
Frame ──► Detection ──► Track ──► Event (the retina.event standard)
│ │ │ │
image one object the same "something happened":
+ ts in one object zone.enter / zone.dwell /
frame over time line.cross / count.threshold
│
└────────► WorldState (the assembled snapshot:
entities + relations + scene latent)
Frame— the append-only unit flowing through the pipeline. Each stage enriches it (the detector fillsdetections, the tracker fillstracks, the rules fillevents) and never overwrites an upstream field. It carries the rawimage, a timestampt, and asrcid.Detection— one object found in one frame: alabel, abbox, aconfidence. This is the model-agnostic seam: a detector is anything callable that maps a frame to alist[Detection]. YOLO, a VLM, Grounding DINO, or your own function — Retina never imports a model.Track— the same object given a stableidacross frames (so "person 42" is the same person from frame to frame). Tracking is what makesline.crossanddwellmeaningful: they need object identity.Event— a transition in the closedretina.eventvocabulary (zone.enter,zone.exit,zone.dwell,line.cross,count.threshold). Tiny and flat like a JWT: three required fields (type,t,src), everything else optional and omitted when absent. See the event spec.WorldState— the state the events transitioned into: the set of entities present at one instant, their relations, and an optional scene latent. Where anEventis the delta, theWorldStateis the frame it applies to. Stream it withPipeline.run_states()alongsiderun().
The dual channel: symbolic core + latent vec¶
Every entity and every event carries a symbolic core (readable, model-agnostic
— id, label, zone, …) and an optional model-tagged latent vec on the
same record. The two are never collapsed: symbols you can read in a dashboard or
feed an LLM; vectors a downstream dynamics model can predict on.
The vec channel is a real serializable interface (Vec(model=..., dim=..., values=...)),
attachable by hand (cookbook recipe 4) or
filled automatically by a shipped producer (DinoV2Embedder per-object,
VJepa2Embedder scene-level).
The pipeline¶
The stages above are composed into a linear chain. Same chain, three altitudes — pick yours:
# 1. `|` composition (LCEL / n8n-style, no GUI)
pipe = YoloDetector("yolo11n.pt") | IoUTracker() | ZoneRule(dock) | JsonlSink("e.jsonl")
# 2. explicit node list
from retina import Pipeline, DetectorNode, TrackerNode, RuleNode
pipe = Pipeline([DetectorNode(yolo), TrackerNode(), RuleNode(ZoneRule(dock))])
# 3. declarative JSON ("n8n without a GUI" — shareable, no code)
pipe = Pipeline.from_json("workflow.json")
Each step is a Node (Frame -> Frame, or None to drop the frame). The
shipped detector / tracker / rule / sink objects auto-wrap into the right Node, so
you usually only reach for an explicit Node to wrap a raw function of your own.
For the common detector → tracker → rules case, Retina(detector=..., rules=[...])
is sugar over a Pipeline.
Where Retina sits¶
In world-model terms Retina is the encoder — s = Enc(x) — and only the
encoder: raw signals in, one standardized WorldState out. Perception backbones
(YOLO, DINOv2, V-JEPA 2, SAM, VLMs) feed it; dynamics and policy build on top of
the state it emits. Swap the model in front or the dynamics behind — Retina is the
constant in the middle.
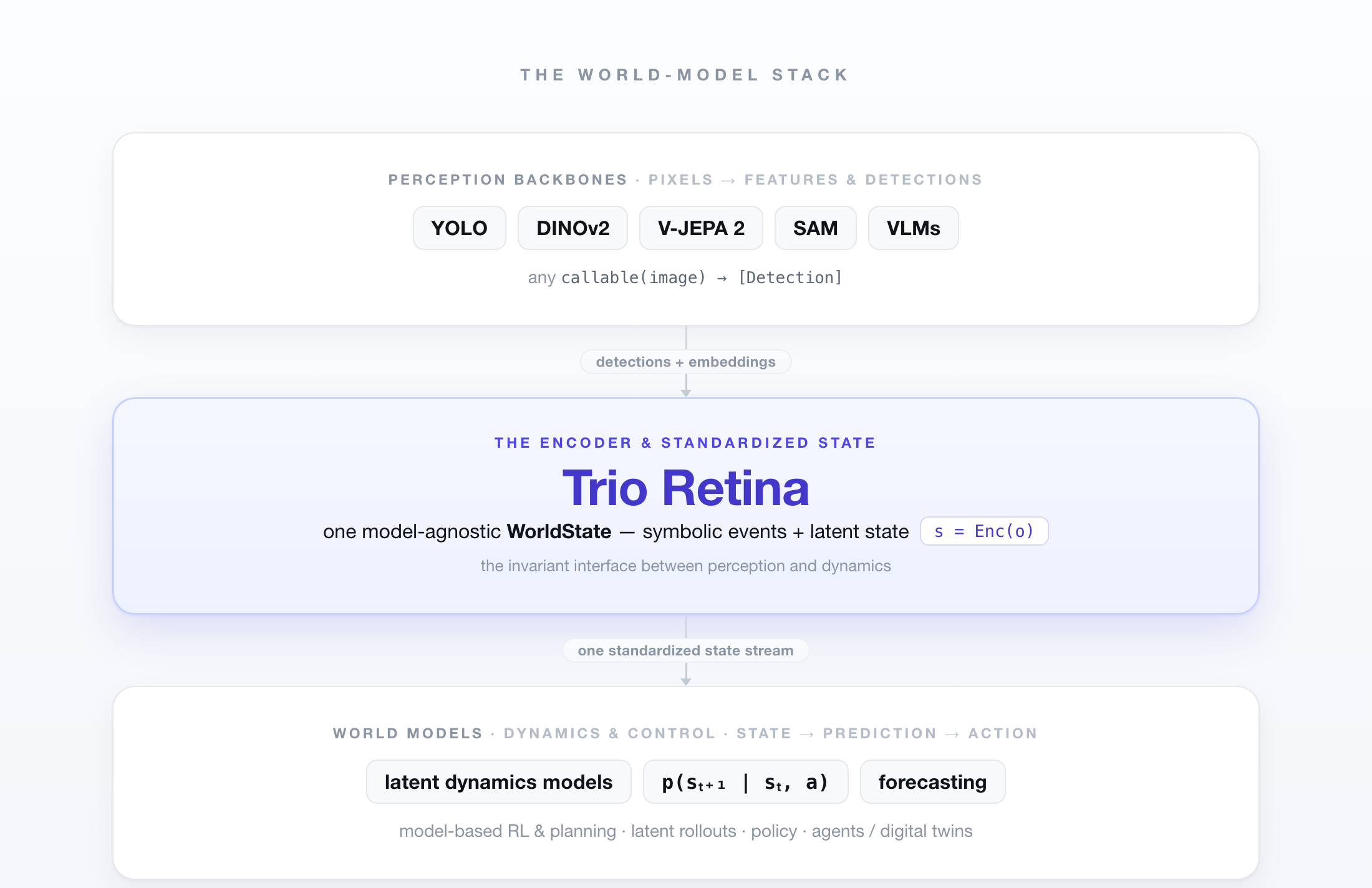
That's the differentiator versus a toolbox like Supervision: Supervision turns a model's output into detections + overlays (great, ends at the screen); Retina emits a serializable state + event stream the next layer (dynamics, a digital twin, an agent) consumes. We compose detectors, not compete with them.
→ Try it now in the cookbook, wire your own pieces in extend, or drive it from the CLI. The full rationale lives in the design notes.